February 4, 2021
In a world that is becoming increasingly more digital by the day and, where cloud computing and IoT are beginning to dominate practically every aspect of our daily lives; data, and the ability to store and access it, is king. Businesses today recognize the value of such data and the impact it has on their future success.

It comes as no surprise then that businesses the world over, encompassing nearly every industry, are generating exponentially more volumes of data today than ever before, a majority of which is unstructured. They are also retaining, re-using, and analyzing the data to a far greater extent today than just a couple of years ago. As a result, data capacity growth is the greatest challenge facing most organizations today, especially those in industries that generate and use vast amounts of data. It is not surprising that the demand for affordable and easily scalable storage is increasing by the day and is considered a vital component for any business’ long-term success. In fact, the capacity requirements for unstructured data is growing by more than 50% year over year.
In fact, if you were to take a step back and take a broader look, the numbers are simply mindboggling. According to a whitepaper by IDC, titled ‘Data Age 2025’, in 1986 the world’s combined data totaled just 2.6 exabytes (EB). By 2018, over 33 zettabytes (ZB) of data was generated worldwide (1 ZB = 1,000 EB). By 2025, the amount of usable business data is expected to rise to 175 ZB, a compounded annual growth rate of 61 percent! Moreover, it is expected that unstructured data would amount to over 80% of the total.
But it doesn’t end there. Over the next seven years, the storage industry is expected to ship about 42ZB of capacity. And by 2025, 90ZB of data will be created on IoT devices and 49 percent of all data will be stored in public cloud environments. Moreover, nearly 30 percent of the data generated will be consumed in real-time.
What is Object Storage?
Until object storage was introduced, traditional data storage architecture such as File Storage and Block Storage were what most businesses used. The former is one most people are familiar with. It is a hierarchical storage system where files are stored in directories and sub-directories. Each file also has a limited set of metadata associated with it, such as the file name, the date it was created, and the date it was last modified.

Block storage on the other hand, is a system where data is stored in chunks called “blocks” with no attached metadata and the address as the only identifying part of a block. We will get into the differences between these storage systems in greater detail later in this blog post but taken as a whole, each system has its own distinct advantages. However, neither of the two, by the very nature in which they operate, are not very scalable.
Furthermore, their architecture does not facilitate the nature of unstructured data very well. This is because unstructured data comprises largely of data such as emails, videos, photos, web pages, audio files, sensor data, and other types of media and web content. Such data does not easily conform to, or cannot be organized easily into, a traditional file system.
Object storage, also referred to as object-based storage, on the other hand, is a data storage architecture that manages and manipulates data storage as distinct units, called objects. It essentially bundles the data itself together with completely customizable metadata tags and a unique identifier and places everything into a flat address space, called a storage pool. As a result, it effectively eliminates the need for any folders or blocks and its flat nature and reliance on metadata not only makes easier to locate and retrieve your data but also makes for easy scalability by simply adding in additional nodes. This linear nature also makes it the perfect data storage architecture for handling large amounts of unstructured data.
The Inner Workings of Object Storage
Every data storage architecture needs a way to index or locate, information so it can be managed and retrieved. Traditional architecture, as mentioned earlier, either use a hierarchy or direct addressing. Unfortunately, such indexing systems have built-in limits and may suffer from performance degradation as they grow closer to their theoretical limits.
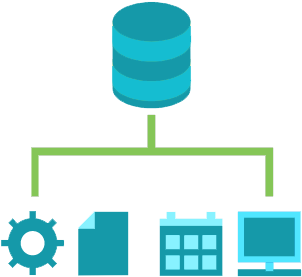
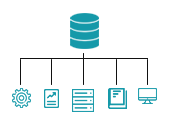
Object Storage on the other hand utilizes a vastly different structure. First and foremost, it stores files as discrete units of data called “objects” in a structurally flat data environment. Each object is a simple, self-contained repository that includes the distinct components – the data that is being stored, all related metadata, and a unique ID number. Similar objects are then organized into groups or containers called “buckets” based on their metadata. Furthermore, object storage uses a clustered system wherein every node in the cluster can see and retrieve data.

These nodes themselves are nothing more than standard stand-alone devices such as industry servers or software-defined storage. Each has its own metadata catalog to identify where the cluster data is stored and can respond independently to data requests. Expanding a cluster is as simple as adding a node to it, in turn, making it easily scalable. Furthermore, multiple nodes can easily be arranged to work in parallel with each other to speed up data retrieval if necessary. Because all data is stored in such a manner in a flat address space, retrieving data is as simple as asking for it by its object ID, regardless of the size of the file or the storage system.
Object Storage vs Traditional Storage
As mentioned earlier, there are two types of outside of data storage architecture that are commonly used outside of object storage – namely file-based storage and block-based storage. Object store, in no way, is the be-all and end-all of future storage systems. Each type of storage has its own advantages and disadvantages. Every business has its own storage requirements and finding that perfect combination of these architectures is what will best fulfill your data storage needs. But to do so, you will first need to understand the differences between each and how they work.
File Storage
File storage has been around for considerably longer than object storage, and as mentioned earlier, is the one most people are familiar with. It is a hierarchical storage system where files are stored in directories and sub-directories.

In addition to the filing structure, each file also has a limited set of metadata associated with it, such as the file name, the date it was created, and the date it was last modified. Each file also has its own unique address making such a file system easy to navigate for most users and works great when dealing with smaller amounts of data. However, once your data starts growing, it’s easy to see how this structure starts to get increasingly more complex and begins to deteriorate in usability and speed of data retrieval. This is further exasperated by the fact that there isn’t a standardized file naming convention that everyone adheres to; as a result, the number of files that can be stored using this system has a finite limit. Furthermore, file sharing using this file system works great for local networks but will face issues when used over a wide area network.
Object storage overcomes two key limitations that traditional file storage faces – scalability and the fast retrieval of large amounts of data. However, if you are primarily dealing with retrieving smaller or individual files, and relatively low amounts of data, then file storage outshines object storage in terms of performance by a significant margin.
Block Storage
With block storage architecture data is stored in chunks called “blocks” with no attached metadata and the address as the only identifying part of a block. Furthermore, any single block usually houses only a portion of the data, with the address as the only identifying part of said block. When data needs to be retrieved, the application makes a call to find the correct address of all the required blocks and data is retrieved and organized to provide the complete file. The very nature of block storage makes it an ideal fit for applications that require high performance, especially if said application and storage are local, but leads to latency issues when working remotely. The architecture, like traditional file storage, has finite limits for the total amount of data stored.
Outside of its scalability, the greatest advantage that object storage has over block storage is the addition of detailed metadata that latter lacks. This allows for much better identification and classification of data as well as easier searchability and retrieval of data that is normally cannot be easily searched such as images and other media.

Why You Should Consider Object Storage?
There are many reasons to consider an object-storage-based solution for your business. Here are just some of them:
- Storing and managing unstructured data
Unstructured data is typically static but may be required at any time and anywhere. Cloud-based object storage is ideal for long-term data retention, in turn making it an ideal storage solution for such files. Moreover, is perfect for the archival of large amounts of rich media content that is not frequently accessed as well as for mandated, regulatory data that must be retained for extended periods of time.
- Scalability
As mentioned before, the structurally flat data environment of object storage together with its use of clustered nodes means that expanding storage is as simple as just adding additional nodes in parallel. In fact, object storage can offer you theoretically limitless storage so long as you can continue adding more nodes to the cluster.
- Reduced Complexity
Object storage removes the complexity out of data storage that traditional file storage systems face, leading to better overall performance, especially when managing and retrieving very large quantities of data.

- Data Protection
Object storage is incredibly flexible and is capable of integrating robust data protection allowing you to protect yourself from whole-device failure, rack failure, or even site failure. There are two key layers of protection commonly utilized by object storage – erasure coding and data replication.
Erasure coding breaks the data into smaller segments and writes them to multiple nodes within the cluster. These nodes may be located at one data center or distributed across multiple for added data durability.
Data replication on the other hand, writes identical copies on multiple nodes. This can even be don’t independently for each of the data segments if required and can replicate and operate across multiple sites as well. In doing so a duplicate disk is always available, ensuring that the system continues running with no interruption or performance degradation, even in the event of a complete site failure.

- Customizable metadata
Considering that each object is a complete self-contained repository that includes all metadata associated with it, searching for and analyzing data is incredibly easy. Better still, the metadata for each object can easily be customized and updated overtime if required.
- Affordability
In most cases, object storage services use a pay-as-you-go pricing model with no upfront costs. Pricing is simply determined by the specified amount of storage capacity, data retrieval, bandwidth usage, and API transactions. Furthermore, given that object storage utilizes industry-standard hardware, acquisition, and maintenance costs are always kept low. The modular nature of object storage cluster expansion means you will not be required to plan capacity increases in advance nor pay for the storage you’re not using.
- Cloud compatibility
Object storage works seamlessly with any cloud or hosted environment, even if they deliver multi-tenant storage as a service. This shared storage approach further optimizes scalability and cost while at the same time reducing the need for on-site IT infrastructure.
In addition, what many may not know is that nearly all major web services or major public cloud storage services are based on object storage technology. In fact, large-scale object storage was first adopted in the cloud. As a result, cloud integration is built right into the very architecture of object storage. This offers object storage incredible levels of modularity and flexibility; so much so that public and private clouds can even be merged into a single storage pool if required. Going a step further, multi-cloud systems allow you to even merge cloud storage from multiple vendors, including the likes of Amazon, Google, and Microsoft, into a single pool with one set of management APIs.

- Standardized S3 API
The Amazon S3 Application Programming Interface, or more commonly known as the S3 API, is the current standard for handling the storage, management, and retrieval of data when using object storage. First introduced in 2006, Amazon’s Simple Storage Service (hence the “S3”) is the object storage protocol that most current major open-source technology solutions adhere to. However, many service providers offer their own APIs as an alternative, each with their own unique capabilities, but in most cases these APIs are fully S3-compatible

ODP Object Storage
Oman Data Park offers object storage (OJS) that gives enterprises the ability to leverage the latest advancements in cost-effective storage technology that is fast, secure, and complies with data regulations.
Our OJS is a scale-out object storage system designed to manage immense amounts of unstructured data. It is an SDS platform which runs on any standard x64 server platform which dramatically reduces the cost of data center storage while providing limitless scalability and availability as well as unprecedented reliability.
Regardless of if your application runs in a Public Cloud (i.e. AWS, Azure, Google) or runs from Onprem environment (i.e. VMware, Hyper V, Oracle Virtualization, Baremetal Server) that needs object storage to access, our OJS provides an open API to integrate with any application, server, or cloud native application.
In fact, the service is extremely simple and flexible to use, starting with a friendly self-service portal that allows users to select and allocate storage as they need it. Users can set quotas and usage rates for groups to maximize efficiency. Access tiers can be configured and work with Amazon S3, Glacier, Google Coldline, or other S3 endpoints.
Speed is boosted by lowering latency. This is achieved through a single site or multi-site system. Choosing the best, most local data center increases speed. We offer object storage from our Rusayl (KOM) and Duqm Data centers, which minimizes the latency for your application by connecting to the nearest datacenter. Built-in data compression also reduces file size, while a GPS Object Locator helps reduce search times.
We also guarantee data security as we are already a secure data center with numerous awards and security certifications. OJS security is further strengthened by SSL encryption, while data at rest is secured by AES 256 encryption for an extra layer of protection.